
Digital twins are having a moment, though the concept itself is not new. The phrase usually refers to a dynamic digital representation of a physical object, environment, process, or even person—one that can be continuously updated through data, simulation, and feedback loops.
The origins of digital twinning are often traced back to NASA and the Apollo era, when engineers relied on mirrored simulations to diagnose and respond to spacecraft failures such as the Apollo 13 incident. Later, the concept became formalized through industrial engineering and systems modeling, particularly through the work of Michael Grieves in the early 2000s.
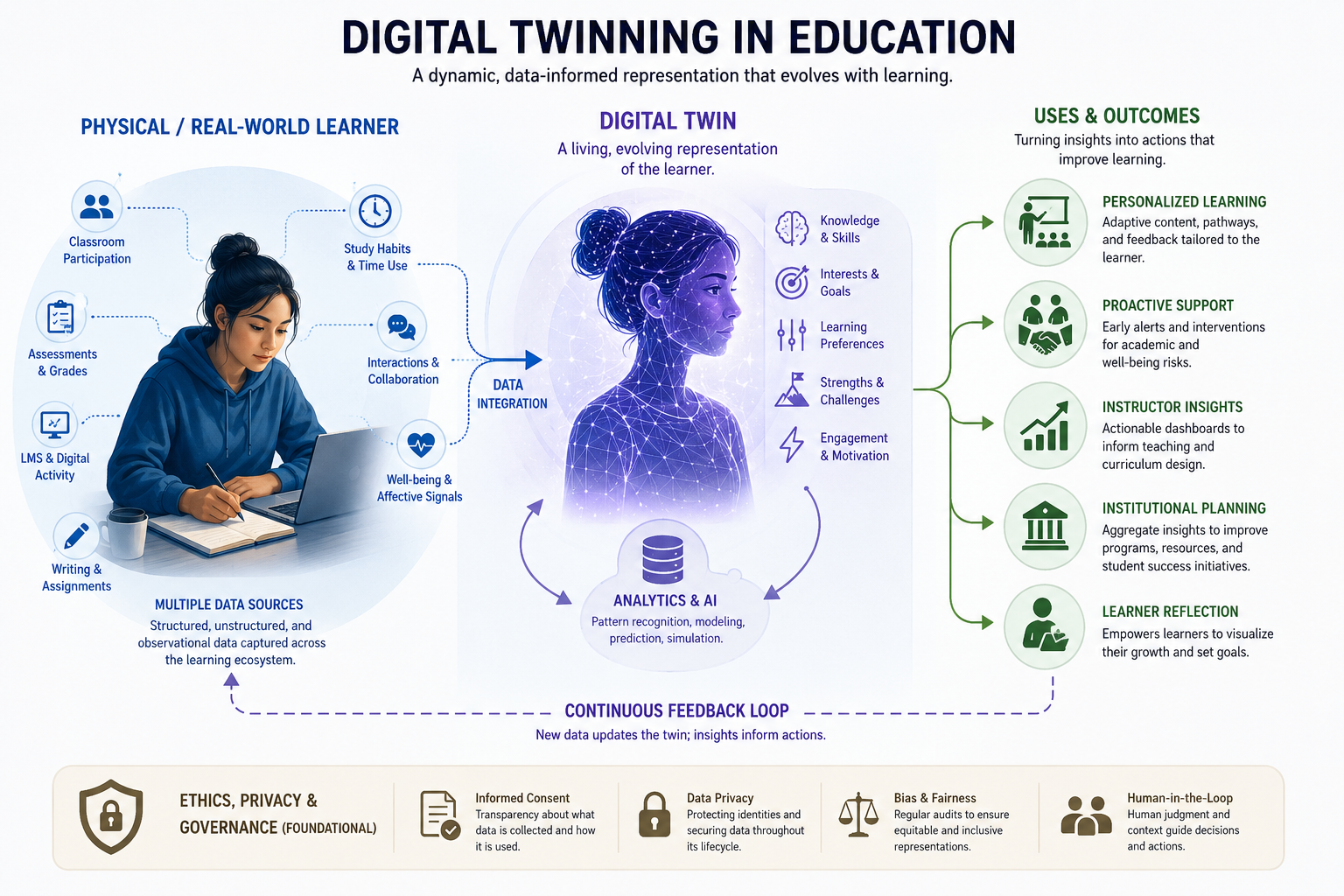
Today, digital twins are no longer confined to aerospace or manufacturing. Universities are already experimenting with campus-scale twins that model infrastructure, energy use, transportation, and student movement patterns. More interestingly, though, higher education is beginning to explore digital twins of learning itself: adaptive student profiles, simulated laboratories, AI-generated instructional environments, and predictive systems that attempt to model student progress over time.
A useful way to think about digital twinning in education is not as a literal “copy” of a person, but as a layered representation of learning activity. Learning management systems already generate fragmented versions of students through attendance data, quiz attempts, analytics dashboards, and engagement metrics. AI systems intensify this process by synthesizing writing habits, communication styles, revision histories, interaction patterns, and even affective signals into increasingly coherent profiles. The emerging shift is not simply toward more data, but toward systems capable of simulating possible futures: which students may disengage, which assignments may fail to motivate, which instructional approaches may improve retention, or which learning pathways are most likely to succeed.
In some ways, higher education has always relied on crude forms of twinning. Grades, transcripts, standardized testing, and assessment rubrics all function as abstractions of learners. What changes now is the scale, granularity, and responsiveness of those abstractions. AI allows these models to become increasingly interactive and predictive rather than merely archival.
Digital twinning is not entirely futuristic. Many people already participate in simplified forms of twinning through social media and platformed digital life, often without recognizing it as such. Consider the relatively ordinary act of following a professional association, advocacy organization, subreddit, YouTube creator, or university page—not necessarily because one intends to engage immediately, but because one wants to “keep tabs” on a stream of information that may become relevant later. In effect, the user deploys a kind of shadow twin: a persistent, low-effort proxy that monitors a domain on the user’s behalf. Platform algorithms then reactivate that connection at opportune moments through recommendations, resurfaced posts, notifications, or targeted content. The system gradually learns what types of information, timing, and rhetorical framing are most likely to draw the user back into engagement.
A similar process already unfolds in literacy practices surrounding writing and research. Graduate students, for instance, often save articles to citation managers, bookmark conference CFPs, follow scholars on academic social media, or subscribe to journals they may not read immediately. These actions create distributed cognitive extensions that function less like static archives and more like ambient intellectual companions. Increasingly, algorithmic systems curate, prioritize, and reactivate these stored associations through recommendation engines and AI-assisted discovery tools. In this sense, many contemporary literacy practices already involve maintaining partial digital twins of our interests, intentions, aspirations, and professional identities across platforms.
What AI changes is the responsiveness and coherence of these systems. Instead of merely storing traces of user behavior, emerging platforms can begin synthesizing those traces into adaptive models that anticipate needs, simulate preferences, and intervene proactively. The distinction between “tool” and “representation” becomes less clear over time.
One foreseeable development is the rise of persistent learning companions: AI systems that accumulate longitudinal knowledge about a student’s habits, rhetorical tendencies, disciplinary strengths, and intellectual growth across courses and semesters. Rather than beginning each class from scratch, future educational systems may maintain evolving “learning twins” that help students visualize their progress, identify gaps, rehearse difficult conversations, or simulate professional scenarios before entering workplaces. Medical education, engineering, aviation, and public policy training are especially likely to move in this direction because simulation-based learning already has strong institutional footing there.
Another likely development concerns writing and literacy practices specifically. As generative AI becomes embedded into everyday composing environments, digital twinning may increasingly operate at the level of rhetorical behavior. Systems could learn how individuals revise, synthesize sources, respond to feedback, or negotiate tone across audiences. A future writing interface may not simply autocomplete sentences; it may anticipate entire rhetorical strategies based on a user’s prior composing history.
For a scholar of digital literacy and design rhetoric like myself, that possibility is both exciting and uncomfortable. On one hand, such systems could support multilingual writers, neurodivergent learners, first-generation students, and those navigating unfamiliar discourse communities by offering more contextualized guidance than generic writing tools currently provide. On the other hand, the same systems could easily drift toward normalization and conformity, subtly rewarding predictable rhetorical patterns while discouraging experimentation, ambiguity, or culturally situated forms of expression.
This is where digital literacy scholarship becomes especially important. The challenge is not merely whether digital twins are accurate, but what kinds of human activity they privilege. Recent research already suggests that AI-generated digital twins perform unevenly across demographic groups and often reproduce existing social biases embedded in training data and institutional systems.
There is also a deeper philosophical issue at stake. The metaphor of a “twin” can falsely imply completeness or equivalence. A digital twin is never the person itself. It is a selective representation shaped by sensors, platforms, metrics, institutional priorities, and computational assumptions. What gets measured becomes amplified; what resists measurement often disappears.
That distinction matters enormously in educational contexts, where learning is often nonlinear, emotional, relational, and socially situated. Some of the most meaningful dimensions of literacy—hesitation, uncertainty, intuition, silence, cultural memory, interpersonal trust—remain difficult to quantify. An overreliance on digital twinning risks flattening education into optimization problems rather than human developmental experiences.
At the same time, rejecting these technologies outright would miss important opportunities. Digital twins may eventually help universities create more accessible learning environments, improve advising systems, test interventions before implementation, and support students through increasingly complex educational pathways. The more productive question is not whether digital twinning will arrive in education—it already has—but what values will shape its implementation.
For educators, this likely means treating digital twins less as replacements for human judgment and more as rhetorical and infrastructural artifacts: systems that require interpretation, critique, negotiation, and accountability. AI-enhanced educational twins may become powerful tools for reflection and support, but they should not become proxies for personhood itself.
Many of us already maintain fragmented twins of ourselves online through feeds, archives, subscriptions, recommendation systems, and behavioral traces. The next phase of digital twinning may not feel like a sudden technological rupture so much as the gradual coordination of systems that are already quietly modeling us in pieces.
The future of digital twinning in literacy practices will probably emerge somewhere between augmentation and surveillance, personalization and standardization, empowerment and institutional control. As outlined in NASA AI ethics, our task is not simply to predict which technologies will succeed, but to decide what kinds of educational relationships we still want to preserve as those systems develop or evolve.
Further reading:
- Understanding digital twins in manufacturing (learn about digital model vs. digital shadow vs. digital twin)
- MIT’s speculation on digital twins and the future of learning
- The impact of digital twinning on campus operational structure (from energy planning to campus maintenance to crisis simulations)
